


This article examines four papers on Grammar Error Correction (GEC) using GPT. Grammar correction includes methods to detect and correct grammatical errors for both native speakers and foreign language learners. Therefore, it is an important area of research as it helps native speakers use language according to norms and lowers language barriers for foreign language learners. There were studies on grammatical errors before GPT, but the main focus was on minimal corrections that did not go against the user's intentions, such as spacing corrections. However, with the emergence of generative models and the diversification of AI language models, user requirements are also diversifying. This is due to the development of models that (1) have improved speech recognition accuracy and (2) can modify entire sentences to sound more natural, like a native language. Here, we examine how well GEC models using GPT can meet these requirements through four papers.
Paper | Is ChatGPT a Highly Fluent Grammatical Error Correction System?A Comprehensive Evaluation | ChatGPT or Grammarly? Evaluating ChatGPT on Grammatical Error Correction Benchmark | Exploring Effectiveness of GPT-3 in Grammatical Error Correction: A Study on Performance and Controllability in Prompt-Based Methods | GrammarGPT: Exploring Open-Source LLMs for Native Chinese Grammatical Error Correction with Supervised Fine-Tuning |
Data samples | CoNLL14, NLPCC18 | CoNLL14 | CoNLL14 | - Total 1,061 parallel data samples collected from websites |
Experiment | Zero-shot (CoT & Few-shot CoT | - Analyzed performance differences based on sentence length
- Investigated cases of under-correction, mis-correction, and over-correction | Zero-shot &
Few-shot | Built a hybrid dataset combining ChatGPT and human annotations |
Target Language | English, German, Chinese | English | English | Chinese |
Results | - Precision and F0.5 scores lower than SOTA models, but higher Recall scores
- Strong in sentence-level fluency and error detection
Weak in document-level error correction such as inter-sentence consistency, pronoun reference, tense errors
- Difficulty in correcting errors across sentence boundaries
- Need improvement in document-level error detection and specific error types
- Less adherence to minimal edit principle and tendency to over-correct
Very high fluency in sentences generated by ChatGPT | - ChatGPT showed lower performance than Grammarly and GECToR on automatic evaluation metrics
- ChatGPT's performance was lower for longer sentences
- ChatGPT tends to naturally change sentence structure and expressions beyond simply correcting errors one by one
- Human evaluation showed ChatGPT had less under-correction and mis-correction but more over-correction | - GEC tasks can be effectively controlled with GPT-3 by providing appropriate task instructions and examples
- Performance tends to improve as the number of examples increases in few-shot settings
- Examples play a more important role than task instructions in controlling model output | - GrammarGPT showed the best performance
- Ranked 1st-3rd in NLPCC2023 SharedTask
- Model parameters are 20 times larger, but data required for fine-tuning reduced to 1/1200 level |
Quantitative Performance Comparison
Performance Report from “Is ChatGPT a Highly Fluent Grammatical Error Correction System?A Comprehensive Evaluation”
English

German and Chinese


Average scores provided by three evaluators for fluency, minimal edits, over-correction, and under-correction
•
Very high fluency in sentences generated by ChatGPT
•
Less adherence to minimal edit principle and tendency to over-correct
Performance Report from “ChatGPT or Grammarly? Evaluating ChatGPT on Grammatical Error Correction Benchmark”

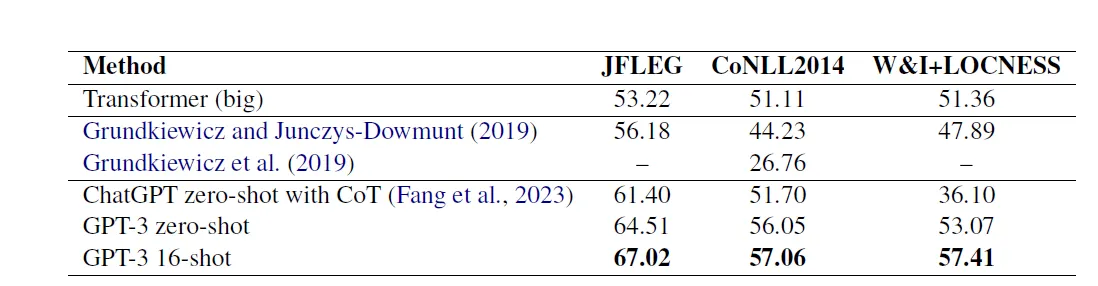
Performance Report from “Exploring Effectiveness of GPT-3 in Grammatical Error Correction:A Study on Performance and Controllability in Prompt-Based Methods”
Discussion Points
•
Grammar error correction (GEC) using general language models (GPT) on CoNLL-2014 is not significantly superior in performance compared to models designed for specific tasks (like Grammarly)
•
If GPT-type models change at the level of rephrasing rather than minimizing edits, it's difficult to trust the above quantitative results that evaluate simple grammar correction ability
•
Regarding controllability to prevent excessive rephrasing, using specific prompts on general models, like GrammarGPT, increases controllability
•
Human evaluation results showing high scores for GPT in fluency but low scores in controllability suggest this may be a case of value judgment issue about the range of modifications to produce more satisfactory results
•
Additional research seems necessary, such as using open-source models or extending to Korean language