


Generative AI를 위한 최근의 기술 동향
Talking about trending technologies like WebAssembly and WebGPUs

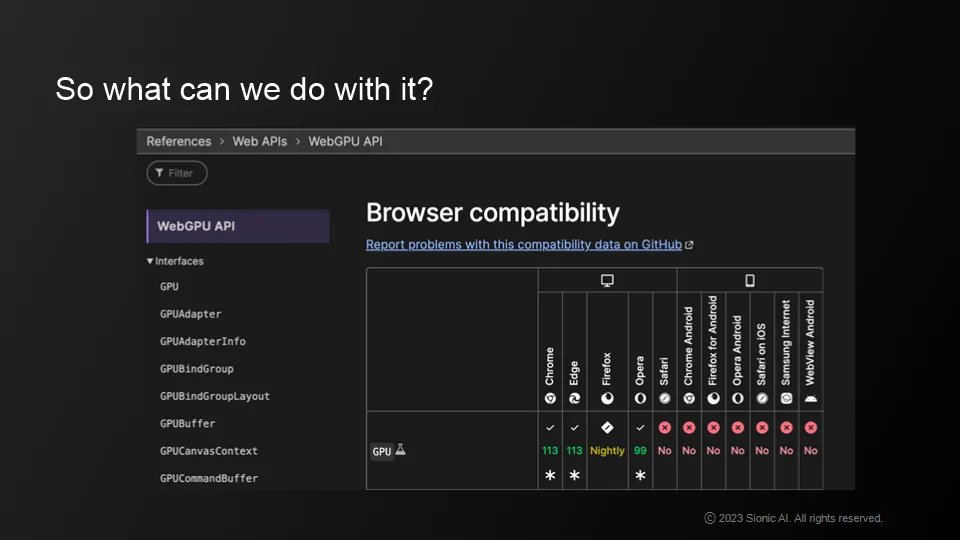
WebGPU
•
Relatively recent use of WebAssembly and others, utilized as a complement to JavaScript rather than a replacement
•
General purpose computation acceleration based on GPGPUs

•
Piloting with Chrome113 in May 2023

•
Microsoft DirectX, Khronos Group's Vulcan, Apple's Metal, etc.

WebGPU structure
•
Web assemblies are composed in native language with web functionality extensions
•
Web assemblies are compiled and passed as files over the web to run
•
Web GPUs display (relatively) high-level API Apapter implementations built on top of web assemblies for high performance

•
Cost and technology of model platforms.
•
Platform-specific behavior, such as native GPU APIs and WebGPU APIs
•
Platforms that distribute diffusion models
•
In addition to model cost and experimentation cost issues, there are standards and technical issues.

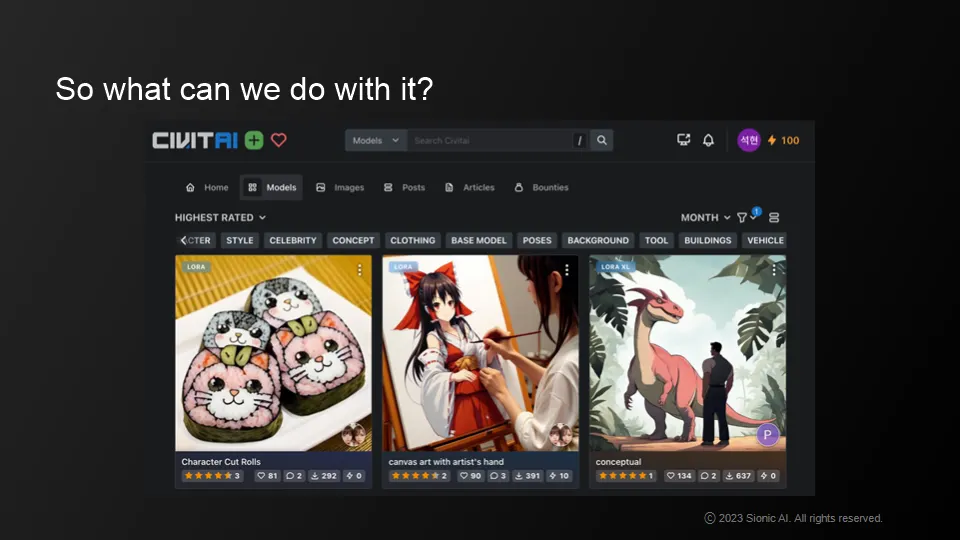
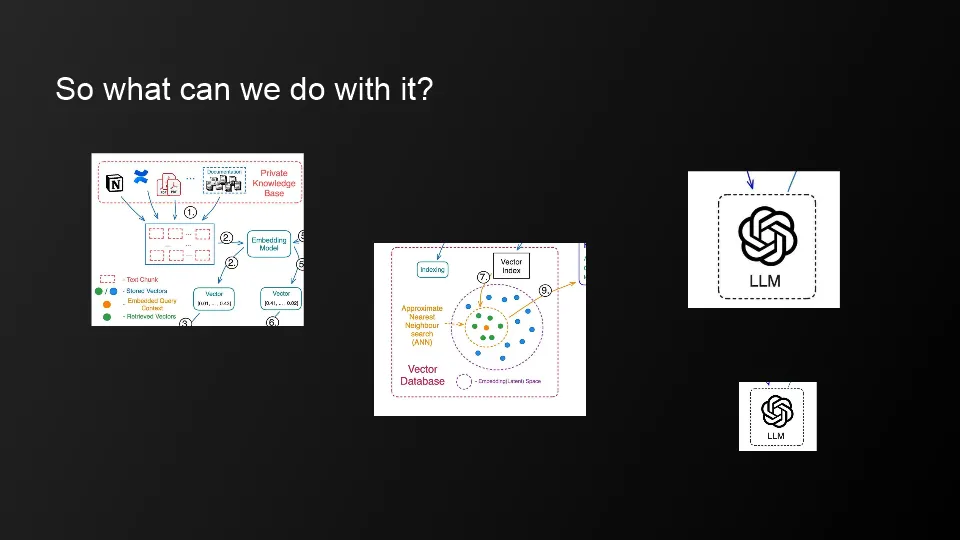
What we can do now
•
AI models for performance and personalization
•
personalized LLM has the potential to revolutionize AR technology when it's on your phone
Native support for Web based applications.
•
Combines the best of Chromium-based open source
•
GPU acceleration in applications built with Electron
•
How to leverage generative AR technology while considering your technical options!
•
Personalized LLMs and isolated GPU modders are a good option, although the infrastructure is expensive to build
•
Personalized LLMs can be put on phones to revolutionize AR technology
•
Now is the best time to take advantage of generative AR technology
•
Higher productivity compared to traditional native GPUs
•
pain point
•
Difficult to fully customize generative AI
•
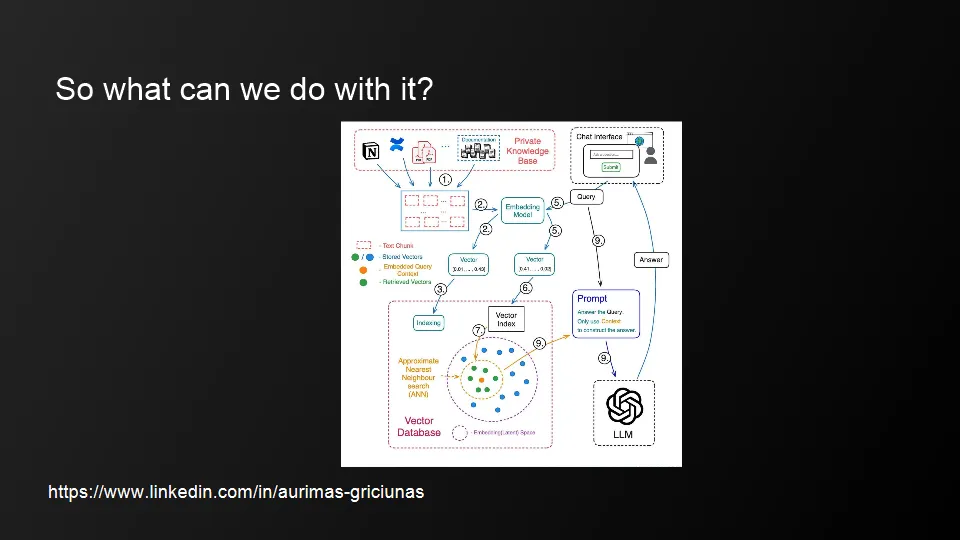
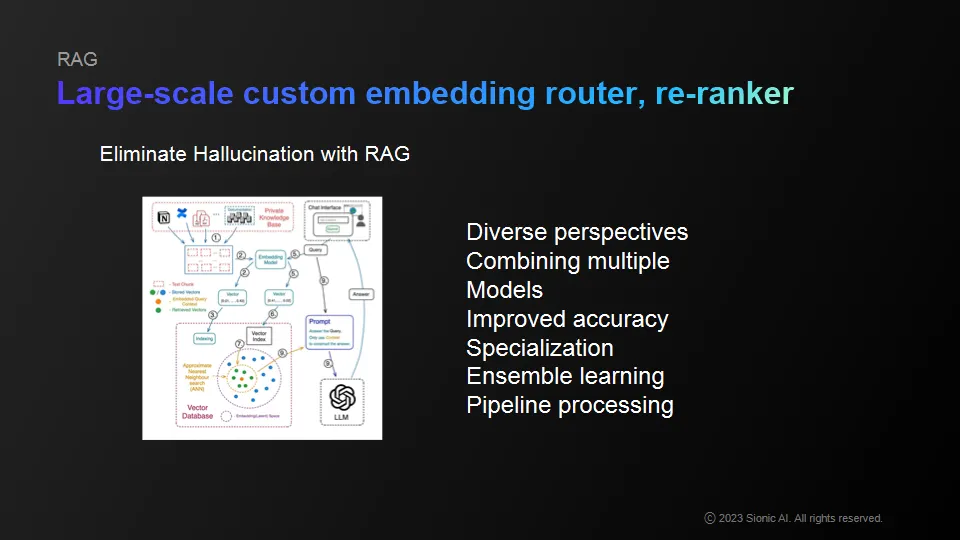
Rely heavily on search-based knowledge or use embedding models
•
Strategic choices we can make
•
Troubleshoot out-of-tune or forgetting existing logical knowledge
•
Reduce the likelihood of private knowledge leaking out
•
Expect quite a few things to be solved with prompt injections via Vector DB
Carry our personalized LLM on your phone and use it to make a positive impact on the world!
Model Configuration
•
Infrastructure is expensive to build, but using a personalized LLM and separate GPU moderator is a good option
•
But mobile support is still in its infancy
Personalized LLM
•
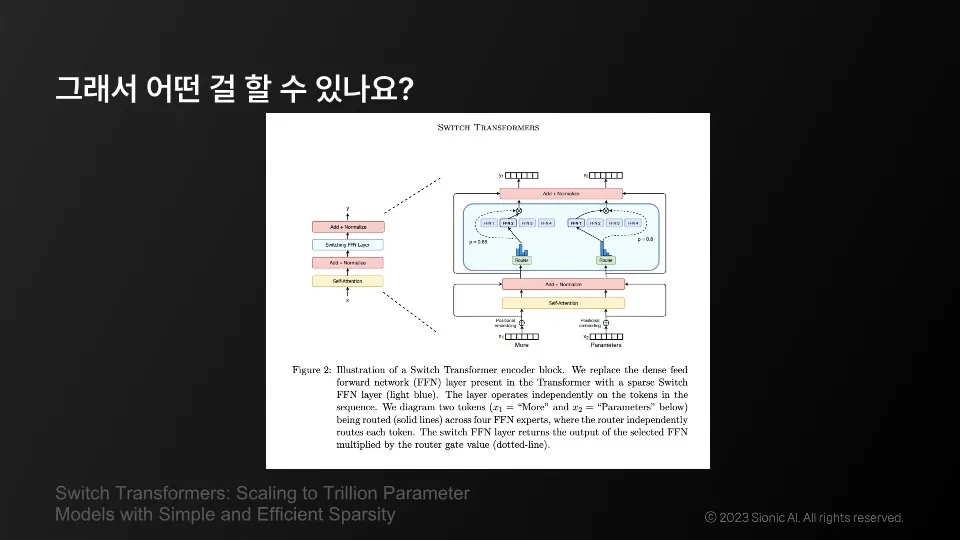
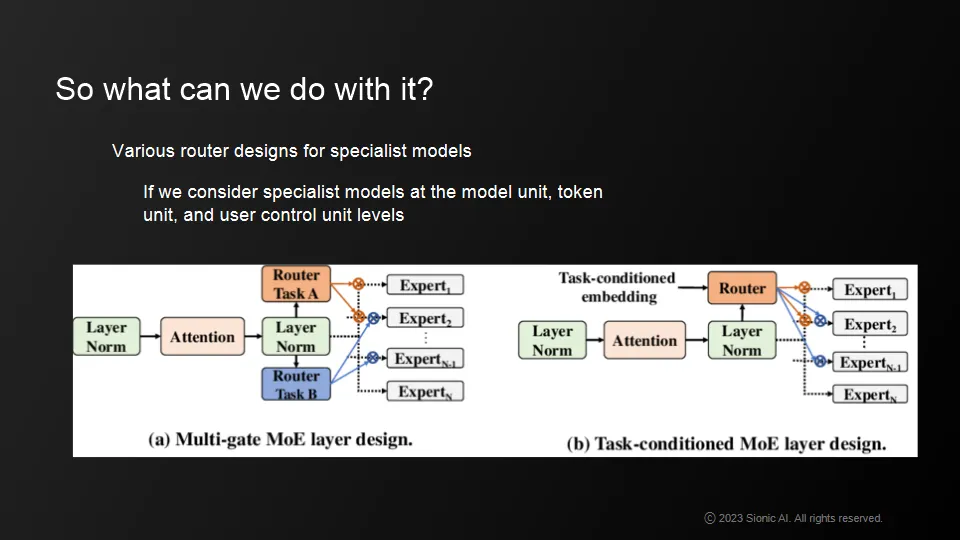
Bringing together multiple specialized models: one for language , one for computational power, one for scientific knowledge and common-sense
•
Bringing a personalized LLM to your phone can transform AR technology
•
Now is the perfect time to leverage generative AR technology

•
A smaller model using WebGPUs is responsible for a more personal LLM, while at the same time pre-directing the logical structure and answer diversity of a larger LLM.
•
Use LLM models with high inference power as a backbone and carry expert models that are more tailored to our company or individual needs on our personal devices (or GPUs, or websites).
How to take advantage of generative AR technology while weighing your technical options.
•
Personalized LMMs and decoupled GPU modders are a good option, although the infrastructure is expensive to build
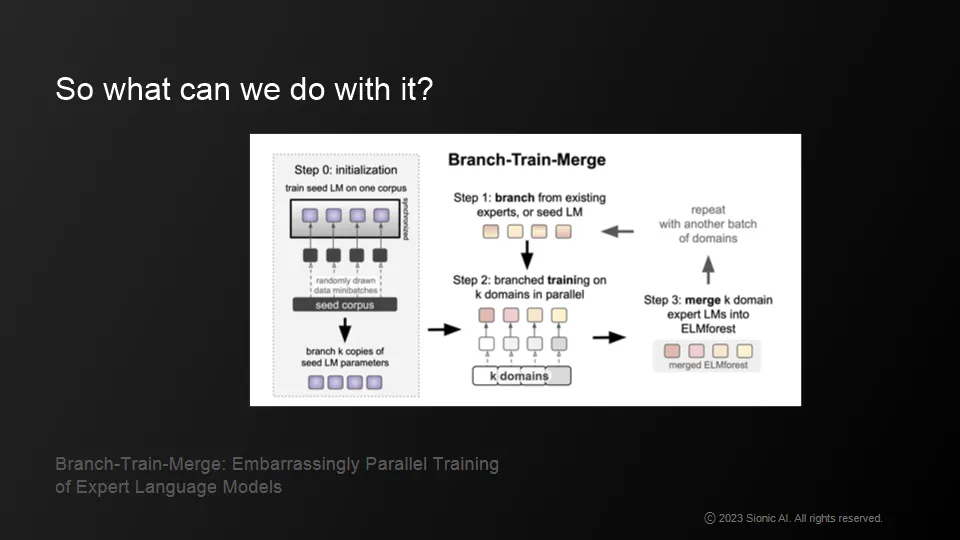
•
Very big developments in open source areas like MLC
•
recently started to see releases for Multi GPU and AMD stuff
•
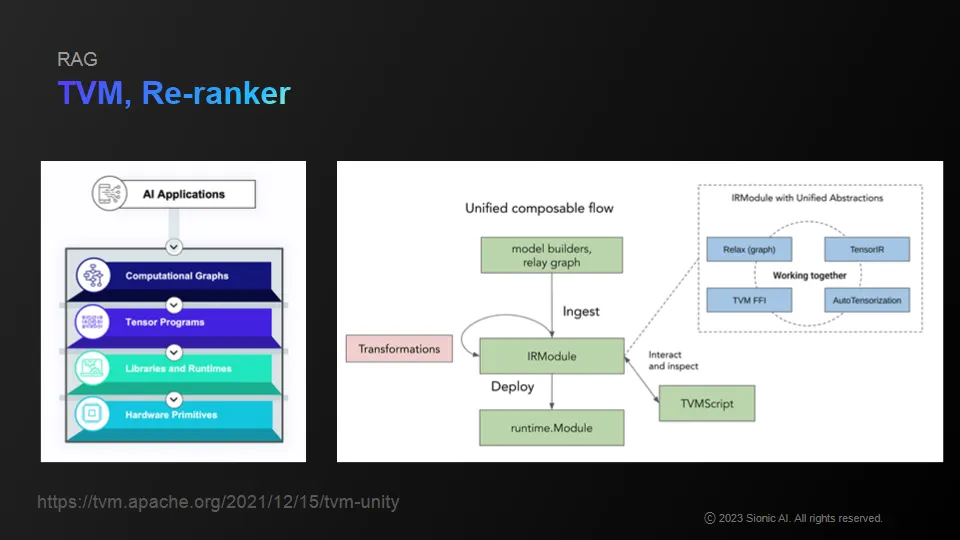
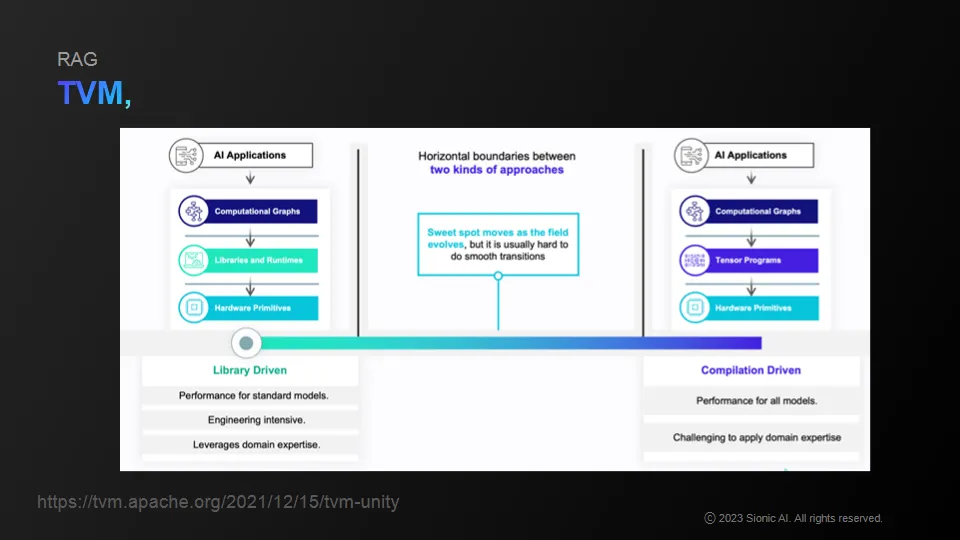
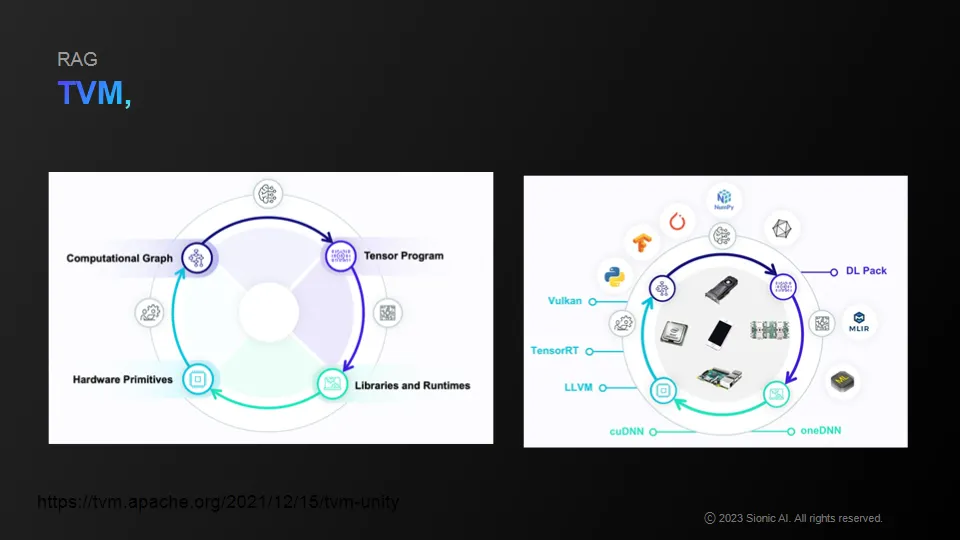
Apache's TVM, etc. allows you to compile ML related pipelines or actual operations.






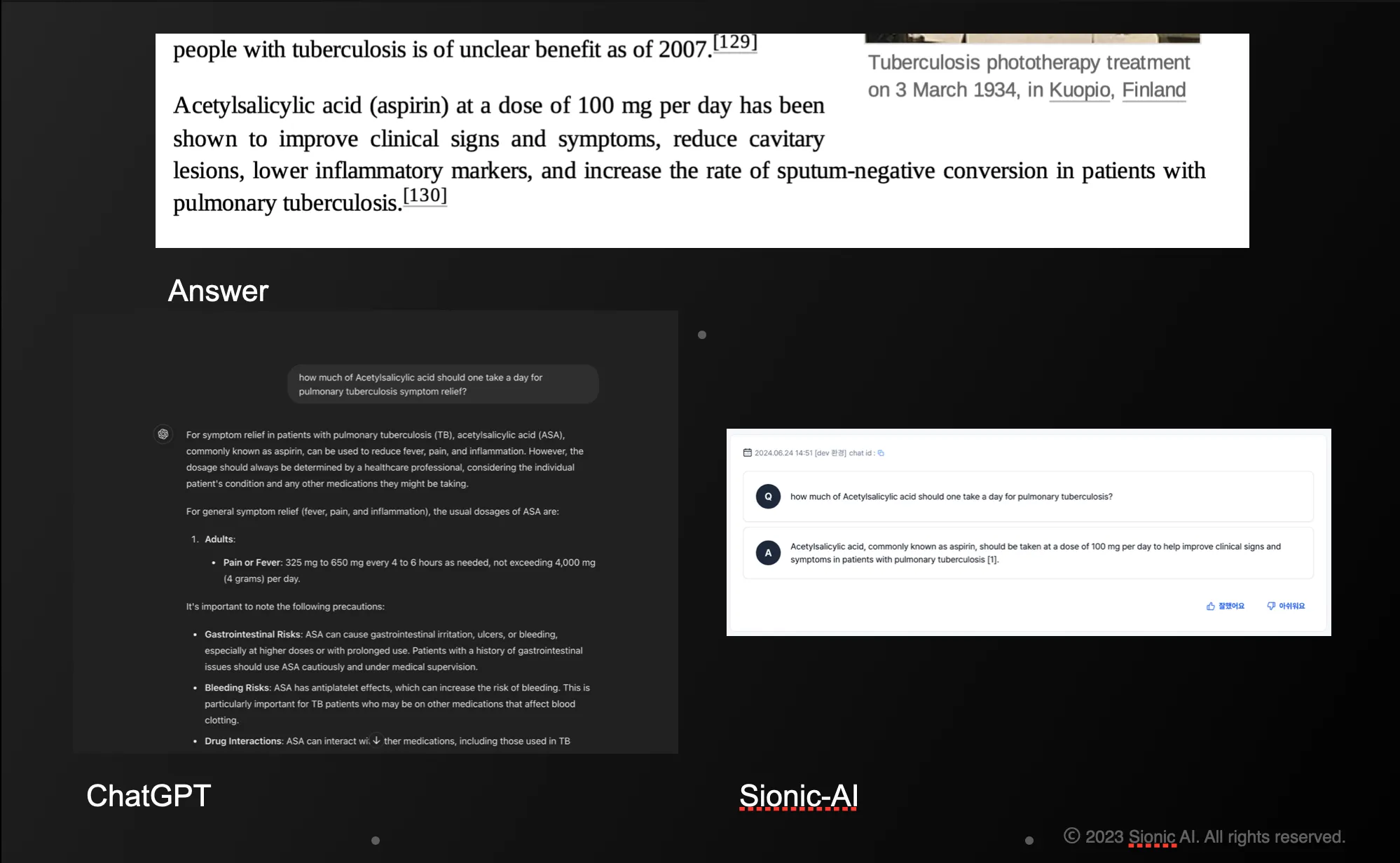
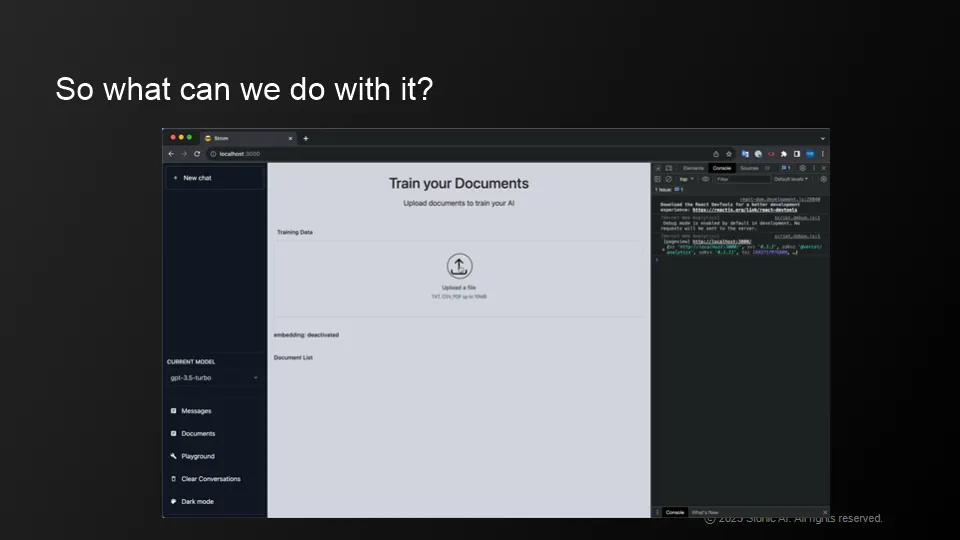
Product evaluation: Storm Answer
•
Compared to ChatGPT, Storm answers are concise and specific to the learned documents and is resistant to hallucination
•
Although its default language is in Korean, Storm provides appropriate answers in english when prompted.