
MTEB(Massive Text Embedding Benchmark)
What is MTEB?
•
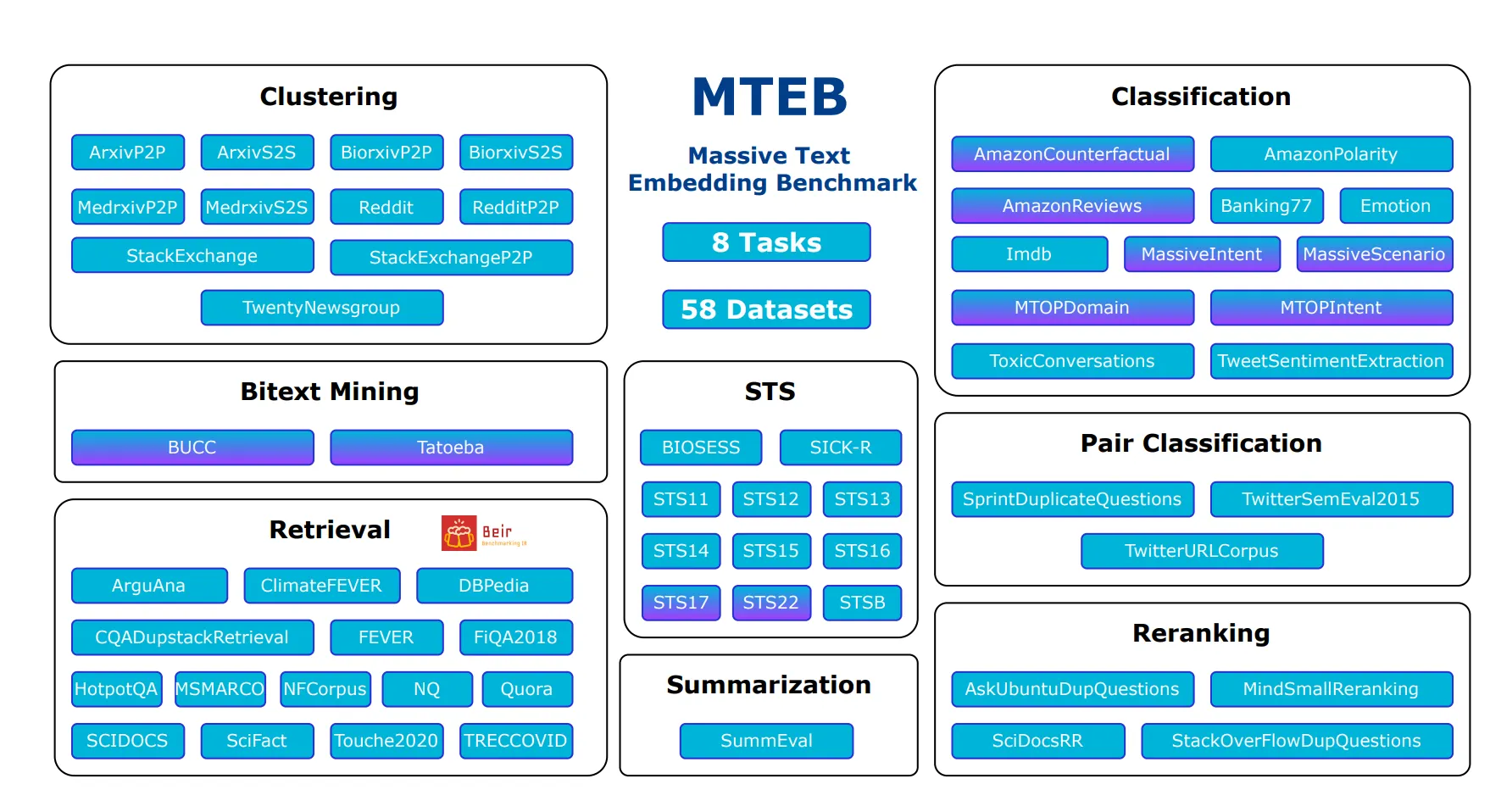
A large-scale benchmark created to measure the performance of text embedding models in various embedding tasks
•
Number of datasets, languages, scores, and models as of October 10, 2023
◦
Total Datasets: 129
◦
Total Languages: 113
◦
Total Scores: 14667
◦
Total Models: 126
References :
https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB (Models specialized for Chinese
Top-performing methodologies within MTEB
1. FlagEmbedding
•
BAAI General Embedding
(1) Datasets and Training Process
•
Pre-training dataset: Pile, Wikipedia, MS MARCO, etc.
•
Fine-tuning datasets: Wikipedia, CC-NET etc.
•
Dataset composition: Questions, positive answers, negative answers
(2) Training Details:
•
Trained using custom base model, RetroMAE
•
Pre-training:
◦
Batch size: 720
◦
Optimizer: AdamW
◦
Learning Rate (LR): 2e-5
•
Fine-tuning:
◦
Batch size: 32,784
◦
Optimizer: AdamW
◦
Learning Rate (LR): 1e-5
◦
Temperature setting: 0.01
•
Feature: Utilizes "hard negative" learning method during fine-tuning
•
Ratio: 1 positive answer, 1 hard negative answer, 65,566 negative answers
(3) Characteristics
•
For retrieval tasks, a special instruction, "Represent this sentence for searching relevant passages:" was added to perform query encoding, and sentences were made relatively longer to mitigate the length difference between short queries and long documents
•
GTE argues that during fine-tuning, because there are hard negative sentences, the batch size need not be very large
•
Negative answers imply responses that are close to being irrelevant
Datasets:
•
Pre-training: 788 million response pairs
◦
Response pairs generated in a manner similar to E5's CCPairs data creation method
◦
Filtering methodology undisclosed
•
Fine-tuning: 3 million response pairs
◦
Various datasets used including MS MARCO, NQ, TriviaQA, HotpotQA, Web Questions, SNLI, MNLI, FEVER, Quora, MEDI, BERRI, etc.
Training:
•
Transformer Encoder
•
MiniLM, bert-base, and bert-large used as backbone models.
•
Vanilla dual-encoder structure with mean pooling used on the output layer
•
Pre-training
•
“Improved” InfoNCE loss

•
Loss calculation:
◦
Typically, the loss is calculated between query and document pairs.
◦
GTE also adds comparisons between queries and between documents in the loss calculation.
•
Pre-training:
◦
Contrastive training with only in-batch negatives.
◦
Due to the absence of hard negatives, used a very large batch size (16,384).
◦
To compensate, limited the max length to 128 tokens.
•
Fine-tuning:
◦
Because hard negative responses are available (random negatives are used for data without hard negatives), a very large batch size isn't necessary. Thus, batch size is set to 128.
◦
Maximum length was set to 512 tokens.
•
Observation:
◦
Simply fine-tuning the backbone model may result in worse performance, possibly due to limitations in data scale.

•
Performance comparison based on the number of training data samples, batch size, and number of model parameters.

Scaling analysis of various factors during contrastive pre-training and fine-tuning.
Model performance is measured by the average performance on MTEB.
•
Characteristics
◦
Uses an approach very similar to E5 with the same model structure, the same backbone models, and similar training methodologies
◦
There are slight differences in the method of generating datasets for pre-training
◦
More data is used for fine-tuning and no teacher model is used
3. E5
•
EmbEddings from bidirEctional Encoder rEpresentations
•
MS
•
Pre-training
•
Constructed a dataset called CCPairs”
•
Pairs are generated in forms such as (query, passage), (post, comment), (question, upvoted answer), (entity name+section title, passage), (title, abstract), (title, passage)
•
Initial Filtering: Heuristic-based filtering is applied to data from Reddit and Common Crawl, resulting in 130 million pairs.
•
Consistency-based filtering: A method where the model is first trained on initially collected data, then the training data is reintroduced to select top-k passages based on queries. Only data with actual mapped passages within k=2 are used. (The key is how much to train and iterate). 27 billion pairs
◦
Neural networks tend to fit clean data first and then overfit to noises in data later on
•
Fine-tuning:
◦
Datasets : MS MARCO, NQ, NLI.
◦
By treating contradictions as hard negatives, the model for NLI is being trained to distinguish between very similar but fundamentally different sentence pairs.
◦
msmarco와 nq는 teacher 모델 (cross-encoder) 에서 추출. Teacher 모델로 SimLM 사용
•
Training
◦
Transformer Encoder
◦
MiniLM, bert-base, and bert-large are used as backbone models.
◦
Uses a Bi-encoder structure with average pooling for the output layer
◦
Pre-training
▪
InfoNCE
▪
Uses in-batch negatives. No explicit hard negatives
▪
Query / passage encoder uses parameter sharing. Instead, prefixes are added (query: , passage: )
◦
Fine-tuning
▪
Uses InfoNCE loss with added distillation loss from the teacher model
•
Discussion points
◦
Slightly better than InstructOR. State-of-the-art at the time
◦
Can reference methods for collecting training data, filtering methods, negative data mapping methods, training techniques, objective functions, and other factors
4. InstructOR
•
The University of Hong Kong, U of Washington, Meta, AllenAI
•
Dataset
◦
Modeling only through fine-tuning
◦
The authors directly constructed the MEDI dataset
▪
A total of 330 different datasets
▪
300 from Super-NaturalInstructions
◦
30 types of Embedding data :Sentence Transformers(https://huggingface.co/datasets/sentence-transformers/embedding-training-data), KILT, MedMCQA
◦
Uses existing embedding model (Sentence-T5) to perform positive / negative mapping
◦
Adds instructions during tuning to enable a single model to operate on various tasks
▪
Example-retrieval) Represent the Wikipedia question for re- trieving supporting documents:(query), Represent the Wikipedia document for retrieval:(document)
•
학습
Training
◦
Single encoder
◦
Uses GTR model as backbone: Initialized with T5 model, then pre-trained on web corpus, fine-tuned on information retrieval datasets
◦
Obtains embedding vector by mean pooling the representation of the last hidden layer
◦
Characterized by having only a fine-tuning stage
◦
InfoNCE


•
Observations
◦
Adding instructions tends to improve performance
◦
When trained on super-NI data, the performance gap between best and worst cases is much smaller. In other words, performance becomes more robust across different instructions
◦
Performance improves as instructions are added more precisely (!)

•
Performance improves with model size (scaling laws)

•
Shows superior performance in unseen domains
Discussion points
•
GTR is a form of T5 pre-training + fine-tuning using contrastive loss on search data
◦
A model that improves performance by collecting additional data for tuning and using prompts tailored to the purpose
Other methodologies worth referencing
•
Sentence-T5