This article introduces the development process and performance of the KoGEC model, which corrects Korean grammatical errors based on Meta's NLLB translation model. (Taeeun Kim et al., 2024)
Research Process
This is the general research process in establishing the KoGEC:
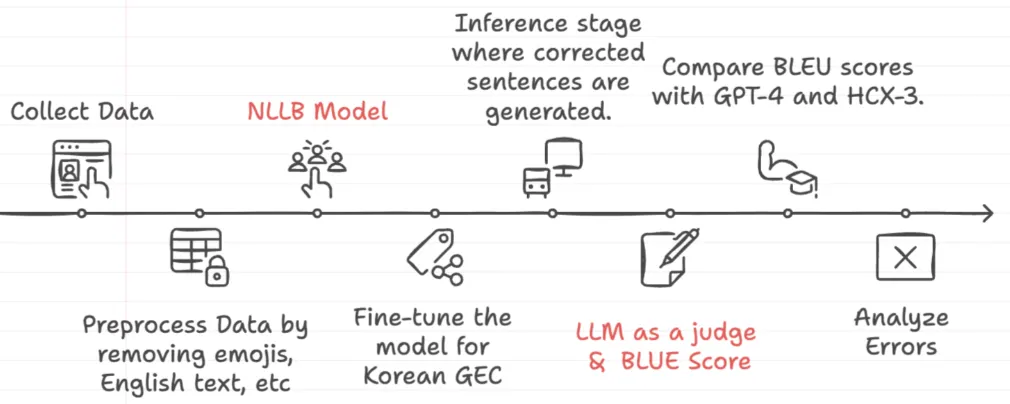
No Language Left Behind (NLLB), Meta’s pre-trained translation model
In our research, we aimed to explore how compact, specialized models can effectively perform Korean GEC tasks. Our focus was on minimizing computational overhead while maximizing performance quality. For this purpose, we selected the No Language Left Behind (NLLB) model as the foundation for our experiments.
The NLLB model is a multilingual translation model designed to support over 200 languages. It is an ongoing project by Meta, that attempts to democratize machine translation even for low-resource languages. Currently, NLLB exists in 4 different model sizes: 600M, 1.3B, 3.3B, and 54B.
1.
Grammar Expertise
a.
NLLB as a translation model for over already promises its excellence in parsing and handling complex grammatical structures, enabling it to address intricate syntax.
2.
State-of-the-Art Performance
a.
Among open-source translation models in its class, NLLB stands among one of few top ranked models.
3.
Efficiency
a.
The 600 million and 3.3 billion parameter models of NLLB were apt to our objective of exploring compact model’s potential in GEC tasks.
Data Collection & Preprocessing
Corpus | Train | Test |
NIKL Spelling Correction Corpus | 393k | 4k |
Korean Error Correction Data | 127k | 1k |
Total | 520k | 5k |
•
We used two datasets: the NIKL Spelling Correction Corpus and the Korean Error Correction Data, totaling 520k training samples.
•
This data was extracted from native conversations on social media which we believed to align with our commitment of modelling for native-level grammar error correction.
•
Due to the nature of conversations that occur on social media, the dataset had to go through a process of cleaning before it was ready for training. We removed emojis and redundant English text that was abundant in the datasets.
Fine-tuning Process
To adapt the NLLB model for Korean grammatical error correction, we introduced special tokens into the training process. Specifically, <ko_Hang> was used to mark the original uncorrected text while <co_Hang> was used to mark the corrected text.
•
By using tokens to mark original and corrected text, the model was explicitly guided to treat this as a translation task, improving its ability to distinguish between errors and corrections.
Training Details
•
Model Variants: 600M and 3.3B parameters
•
Optimizer: Adafactor
•
Hardware: Single NVIDIA A100 GPU.
•
Training Times:
◦
600M: 3 hours
◦
3.3B: 10 hours
Our experiments produced two fine-tuned models:
Results and Analysis
The two fine-tuned models were compared against two state-of-the-art LLMs, GPT-4o and HCX-3. GPT-4o is renowned for its general-purpose capabilities, while HCX-3 is specifically tailored to Korean language tasks, with a significant portion of its pre-training data focused on Korean.
For GPT-4o and HCX-3 inference, we tested two prompting approaches: few shot and zero shot prompting.
Zero-Shot Prompt:
Few-Shot Prompt:
•
“당신은 틀린 한국어 문장을 고쳐주는 표준어 맞춤법 교정기입니다. 주어진 문장을 표준어와 맞춤법 규정에 맞게 고치되, 윤문을 바꾸지 않도록 최소한의 교정을 하세요. 만약 문장의 맞춤법과 띄어쓰기가 틀리지 않고 표준어라면 문장 그대로 출력하세요. 교정된 문장 외 아무것도 출력하지 마세요.”
•
“You are a standard spelling corrector that corrects incorrect Korean sentences. Edit the given sentence to comply with standard language and spelling regulations, but make minimal corrections to avoid changing the sentences. If the sentence has no spelling or spacing errors and is in standard language, print the sentence as is. Do not print anything other than the corrected sentences.”

Zero-shot prompting consisted of a simple instruction shown above. Few-shot was with a comprehensive Korean grammar guideline, which was carefully assembled according to the official Korean grammar and Orthography Rules. Each rule was accompanied with multiple examples. During the testing of both methods, minimal differences were observed, so we opted for the zero-shot method for final evaluations to minimize token input.
To evaluate GEC performance, we used BLEU scores, a standard metric for comparing model outputs against reference texts.
Model | BLEU Score |
NLLB-ko-gec-3.3B | 85.73 |
NLLB-ko-gec-600M | 58.15 |
GPT-4 | 75.03 |
HCX-3 | 71.24 |

Matched data percentages show the exact outputs that perfectly match the ground truth data, indicating fully accurate grammar correction.
LLM as Judge for GEC Model Performance Analysis
To understand model performance, we analyzed the types of errors each model made implementing the 'LLM as Judge' framework. Below is a diagram of the pipeline.
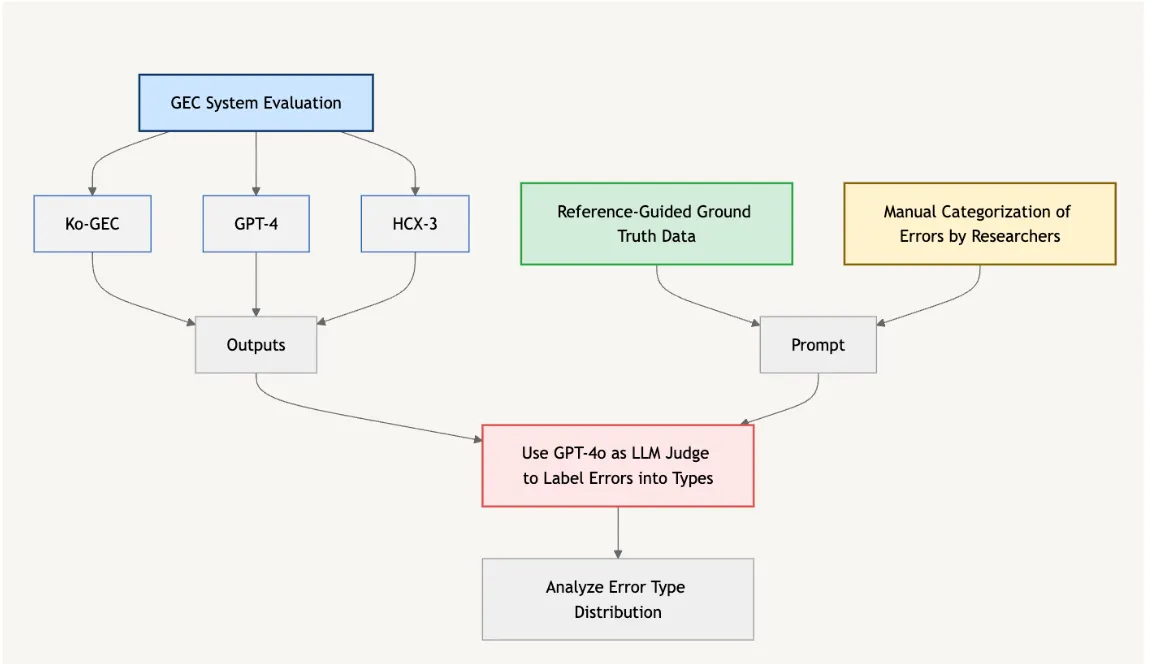
1.
Initially, three different GEC models—KoGEC, GPT-4, and HCX-3 processes the same set of sentences and produces its own version of “corrected data.”
2.
For the errors, we established a taxonomy of general Korean grammar error types referring to previous works by Yoon. This taxonomy identifies 11 distinct error types by a native, such as word spacing, punctuation errors, and verb conjugation errors.
a.
Example Error Type:
WS: Word Spacing, violating Korean spacing rules.
Incorrect: 오징어 볶음 시키자.
Correct: 오징어볶음 시키자.
translation: Let’s order stirfried squid.
PUNCT: Punctuation errors, incorrect use of periods, commas, etc.
Incorrect: 진짜 한번 가 봐 되게 예뻐..
Correct: 진짜 한번 가 봐. 되게 예뻐.
translation: You should really go see it. It’s so pretty.
JavaScript
복사
3.
Reference-guided grading was employed for the LLM judge. The ground truth test data was gathered and given to the judge as a reference to establish clear grading criteria and minimize bias.
4.
With the reference and error categorization, we created a structured prompt to guide GPT-4o in evaluating the unmatched outputs of all three models consistently and objectively. Based on the reference data, GPT-4o labelled each model’s outputs into predefined error categories.

Results:

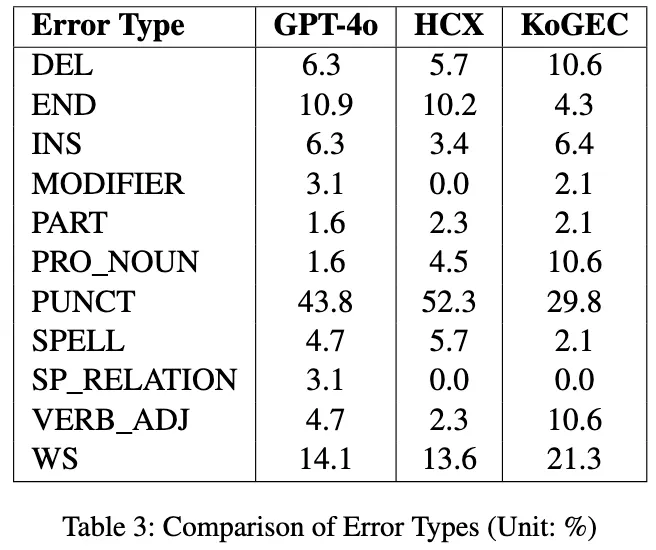
From this analysis, we concluded that KoGEC demonstrates a more balanced error profile compared to GPT-4 and HCX-3. Unlike the other models, KoGEC does not display a significant concentration of errors in a single category, indicating its ability to handle diverse grammar issues effectively.
Limitations and Future Directions
The NLLB tokenizer struggled with Korean’s extensive syllable combinations, leading to performance bottlenecks. Because it accommodates around 200 languages, it lacked depth in representation of Korean’s extensive syllable combinations. Moreover, some tokens in the tokenizer were identified as grammatically incorrect, further impacting the model's understanding of the language.
We see potential in integrating KoGEC with more advanced LLMs like Google’s Gemma. This would allow us to leverage the advancements in representation learning and tokenization, that will help overcome current limitations while enhancing model accuracy.
We’ve open-sourced the KoGEC model on Sionic AI’s HuggingFace in hopes of encouraging further research in Korean NLP. Additionally, KoGEC is accessible to all through the GoodHangul website, where our 3.3B model provides real-time grammatical error correction.